La arquitectura de un buscador se basa en 4 elementos fundamentales:
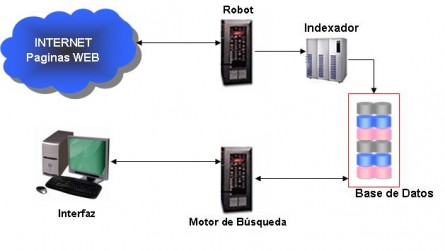
Robot: las bases de datos de los buscadores se suelen construir utilizando robots (programas) que recorren la Web y recuperan los documentos de forma automática. Normalmente los robots comienzan con un listado de URLs preseleccionadas y visitan periódicamente los documentos en ellas referenciados. Los robots utilizan algoritmos para seleccionar los enlaces a seguir, determinar las frecuencia de la visitas, etc.
Indexador: se trata de un programa que recibe las páginas recuperadas por un robot (muchas veces el robot y el indexador son el mismo programa), extrae una representación interna de la misma y la vuelca en forma de índice en una base de datos. Existen varias técnicas para extraer la información del documento, algunos indexadores sencillos almacenan los títulos HTML, otros los primeros párrafos, etc. Pero los más avanzados utilizan técnicas complejas:
- Extracción avanzada de vocabulario de términos:
Listas de stop (o listas de palabras vacías): son listas de palabras muy habituales que no aportan significado y que no deben aparecer en el vocabulario. Por ejemplo preposiciones, artículos, etc.
Extracción de raíces: consigue un termino único para el vocabulario que representa distintas palabras de significado parecido, por ejemplo plurales, tiempos verbales, etc.
- Medidas de la calidad según la frecuencia de aparición de cada palabra en cada documento.
Motor de búsqueda: programa que se encarga de analizar una consulta de usuario y buscar en el índice los documentos relacionados. Los motores de búsqueda suelen estar implementados mediante alguna de las tecnologías que permiten a los programas interactuar con los datos enviados sobre HTTP, por ejemplo CGI, Servlets, ASP, CFML, etc. Un buen motor de búsqueda será capaz de ordenar los resultados de manera que aparezcan antes las páginas más relevantes atendiendo a varios indicadores, entre otros:
· Localización: hace que dentro del resultado aparezcan antes aquellos documentos donde existen ocurrencias de todas las palabras utilizadas en la consulta. La relevancia de los documentos es mayor cuanto más al comienzo de los mismos aparecen las palabras buscadas. Por ejemplo, si todas las palabras utilizadas en la consulta aparecen en el título del documento, este será muy relevante y aparecerá antes en la respuesta que ofrece el motor de búsqueda.
· Frecuencia de aparición: a mayor número de apariciones de los términos de la consulta en una página, más relevante será ésta para el resultado. Algunos motores utilizan una valor de frecuencia máxima y descartan los documentos que superan ese valor. Con esta política se consiguen evitar documentos spam, que intentan subir posiciones en el listado de respuesta sin tener un valor real.
· Popularidad: algunos motores son capaces de medir la popularidad, es decir, el número de enlaces que apuntan a una página. Una página a la que se hacen muchas referencias suele ser mejor que otra a la que se hacen menos.
· Precio: en buscadores comerciales, se están implantando servicios de pago que permiten que una página aparezca antes en los resultados en función de la cantidad de dinero pagada.
Interfaz: la interfaz más utilizada es la basada en páginas Web con formularios:
· Formularios: el mecanismo de entrada de datos de las páginas web son formularios normalmente basados en una caja de texto (en donde el usuario introduce la palabra o frase buscada) y un botón de envío (al pinchar sobre él se envía la consulta). Existen otras soluciones que permiten búsquedas más avanzadas con formularios más complejos que permiten, por ejemplo, introducir varias palabras, añadir expresiones booleanas, buscar en un idioma concreto, buscar por proximidad, etc.
· Páginas web de resultados: los resultados se muestran en una página web en grupos de ítems. Cada ítem contiene una pequeña descripción, el contexto en el que se ha encontrado y el enlace Existen también soluciones más avanzadas que permiten la traducción automática, etc
Los robots no son más que programas que rastrean la estructura hipertextual de la Web, recogen información sobre las páginas, indican la información, la clasifican y conforman una base de datos que es a la que posteriormente acudirán los motores para buscar la información. Los robots o herramientas que recopilan las páginas web para formar los índices de los motores de búsqueda han adoptado distintas y variadas denominaciones, pero todas ellas tienen que ver con la metáfora de la World Wide Web como telaraña o espacio a recorrer y en la cual los robots se mueven y diseminan como:
· Arañas (Spiders): es un programa usado para rastrear la red. Lee la estructura de hipertexto y accede a todos los enlaces referidos en el sitio web. Se utiliza como sinónimo de robot y crawler.
· Gusanos (Worms): es lo mismo que un robot, aunque técnicamente un gusano es una réplica de un programa, a diferencia de un robot que es un programa original. Se usan, por ejemplo, para duplicar los directorios de FTP para que puedan acceder más usuarios.
· Orugas (Web crawlers): es un tipo específico de robot que ha dado lugar al nombre de algunos buscadores como Webcrawler y MetaCrawler.
· Hormigas (WebAnts): cooperativa de robots. Trabajan de forma distribuida, explorando simultáneamente diferentes porciones de la Web. Son robots que cooperan en un mismo objetivo, por ejemplo, para llevar a cabo una indización distribuida.
· Vagabundos (Wanderes): son una clase de robots que realizan estadísticas sobre la Web, como por ejemplo, número de servidores, servidores conectados, número de webs, etc.
· Robots de conocimiento (Knowbots): localizan referencias hipertextuales dirigidas hacia un documento o servidor concreto. Permiten evaluar el impacto de las distintas aportaciones que engrosan las distintas áreas de conocimiento de la Web.
La labor de indización también puede realizarse de forma manual, de forma automática, o combinando ambos métodos. Y la información puede extraerse bien de los datos que proporcionan los autores, como del propio documento, extrayendo la información expresada en metadatos, meta descripciones y palabras clave; o buscando en el propio contenido del documento, en el título, encabezados, analizando los enlaces, frecuencia de ciertas palabras, haciendo búsquedas a texto completo, etc. En este sentido, el funcionamiento de los motores de búsqueda varía sustancialmente de unos a otros y, mientras que algunos realizan un rastreo superficial, otros por el contrario, realizan un rastreo profundo, cuentan con soporte para marcos o frames, rastrean los enlaces por popularidad, tienen capacidad para aprender de la frecuencia con que se modifican las páginas, cuentan con capacidad para rastrear imágenes y texto alternativo, etc.
También los índices que conforman los motores de búsqueda varían en su complejidad. En algunos se trata de una simple lista de palabras que describen el contenido de las URL indizadas o de un fichero inverso, sin embargo, cuando el índice es muy extenso, se presentan numerosos problemas para gestionarlo y se deben introducir una serie de técnicas que permitan reducir el tamaño de la base de datos, como suprimir las palabras vacías, eliminar las palabras derivadas (lematización), convertir las mayúsculas a minúsculas, etc.
